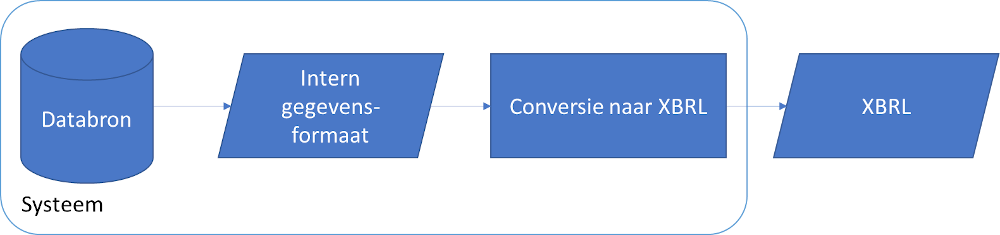
Eén systeem
Indien een softwareleverancier een compleet pakket biedt dat over alle benodigde gegevens beschikt, dan is het mogelijk om direct een complete XBRL-gegevensset te genereren. Vaak zal er nog een tussenstap in zitten, waarbij de gegevens uit de databron omgezet worden naar een intern formaat, al hoeft dat niet het geval te zijn.
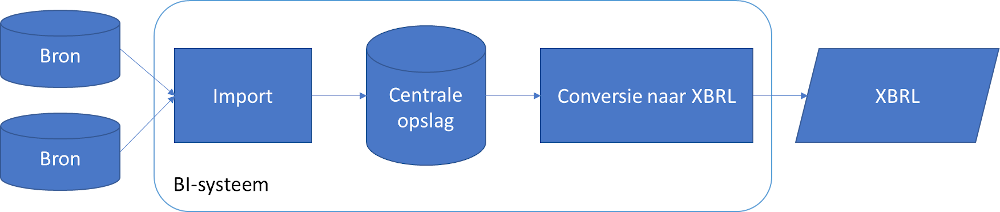
Indien niet alle data in een systeem beschikbaar is, kan één van de softwareleveranciers (of een buitenstaander) een systeem ontwerpen waarbij gegevens uit andere databronnen verzameld worden, om tot een complete gegevensset te komen.
De mogelijke importformaten zijn vaak zeer divers: tekstbestanden, CSV-bestanden, XML, JSON, spreadsheets, etc.
Zo’n centrale database (ook wel een datawarehouse genoemd, al dan niet met Business Intelligence-functionaliteit) zal dan zodanig opgezet moeten worden dat het gegevens kan opslaan voor alle definities die in de taxonomie voorkomen. De kunst is om hierbij wel rekening te houden met wijzigingen in de taxonomie, die het gevolg kunnen zijn van wetswijzigingen. Duidelijke afspraken tussen softwareleveranciers zijn dan wenselijk.
Het gegevensmodel in deze centrale database zal zodanig opgezet kunnen worden dat brongegevens pas worden geaccepteerd indien ze de integriteit van de dataset niet in gevaar brengen: zo zullen bijvoorbeeld optellingen moeten kloppen en mogen er geen strijdige gegevens worden ingeladen.
De omzetting naar XBRL kan op dezelfde wijze verlopen als in scenario 1.
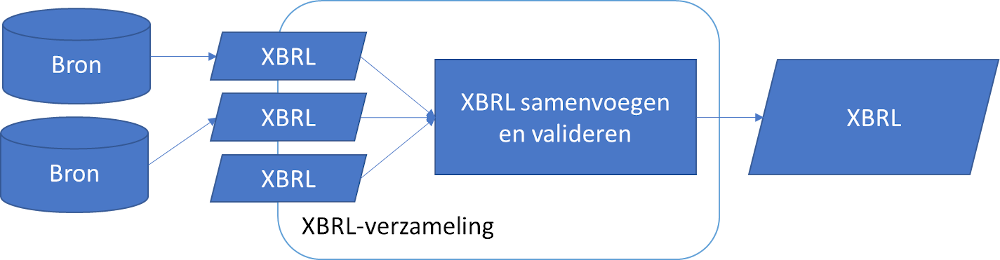
Dit scenario is functioneel vergelijkbaar met het vorige scenario: gegevens van meerdere bronnen worden samengevoegd tot één enkel XBRL-bestand. Het verschil is dat de brondata in deze aanpak als partiële XBRL-bestanden worden verzameld.
Het ontwerpen van een functie voor het samenvoegen van deze XBRL-bestanden vereist wel enige XBRL-kennis (alleen met XML-kennis is de kans op fouten groot), maar is goed te realiseren.
De afzonderlijke XBRL-feiten uit de XBRL-bestanden zullen op een eenduidige manier ingelezen moeten worden (dus XBRL-conceptnaam, XBRL-dimensies, datum, valuta, waarde, etc., waarbij context-identifiers en XML-prefixes genegeerd moeten worden).
Vervolgens kunnen strijdige elementen (bijv. zelfde datapunten met verschillende waardes) gedetecteerd worden en kan er een enkel XBRL-bestand gegenereerd worden, met juist context-identifiers en XML-prefixes.
In bovenstaande scenario’s kan het altijd zo zijn dat specifieke informatie ontbreekt. In al deze scenario’s is het mogelijk om een gebruikersinterface te maken waarin ontbrekende informatie opgevraagd wordt en vervolgens toegevoegd aan de rapportage:
- Een mini-portaal in een cloud-omgeving
- Een dialoogscherm in een desktoptoepassing
- Een hulpbestandje vanuit een spreadsheet
- Gevraagde bijlages (bijv. pdf-documenten)